生成AIプロンプト|SAPの機能(T-CD)がアクセスしているテーブルを調べる

生成AIを使って、SAPシステム(SAP ERP, SAP S/4HANA)の機能名から、その機能がアクセスしているT-CDと、データテーブルの一覧を作成してみよう。
本記事は、ChatGPT や Google Gemini などの生成AIに、貼り付けるだけで使える、プロンプト(命令文)を紹介する。
SAPシステムの中身は非公開
SAPシステムも情報システムの一つ。
そのデータは、リレーショナルデータベース(RDB)のテーブルに保存されている。
たとえば、「品目マスタ」(T-CD:MM01)のテーブルなら、MARA, MAKT, MARC... など複数のテーブルに保存されていることが知られている。
しかし、どの機能のデータが、どのテーブルに保存されているのか、といった具体的な技術情報を、SAP社は公式には公開していない。
SAPシステムの中身は、基本的に非公開なのだ。
個々の機能(トランザクションコード:T-CD)が使用しているテーブルを知りたい場合、SAPコンサルトと呼ばれる、SAPシステムの専門家に尋ねることになる(最近なら、ネットを検索して調べることもできるが)。
いずれにしても、個々の機能がアクセスしているテーブルを、いちいち検索して調べるのは、かなり面倒だ。
でも、面倒な調べ物なら、時短ツール = 生成AI の出番である。
生成AIは、SAPシステムの専門家でもある。
データが格納されているテーブルだって、教えてもらえるはずだ。
この記事のプロンプトサンプルでは、SAPシステムのトランザクションコード(T-CD)を指定すると、そのT-CDがアクセスしているテーブルの一覧表を出力することができる。
このプロンプトで得られる情報
このプロンプトでできること
- 指定したT-CDがアクセスしている、データテーブル(物理名、論理名)の抽出
- データテーブルに保存されている、レコード数の平均
- データテーブルの、用途、特徴などの表示
プロンプトサンプル
# 依頼
あなたは{# 役割}です。SAP S/4HANAのプログラム開発を行うため、S/4HANAのトランザクションコード(T- CD)がアクセスしているデータテーブルの調査をしています。次の{# ルール}を必ず守り、{# 機能名}からS/4HANAの機能名を読み取って、その機能がアクセスしているデータテーブル(透過テーブル)を{# 形式}の形式で出力してください。
# 役割
SAPシステムのコンサルタント
# 形式
- 表形式
- 列は{# データ項目}を参照
# データ項目
":"より左が結果として表示する列名。右が列に表示する内容。
- 機能名:{# 機能名}で与えられたS/4HANAの機能名
- T- CD:機能名に該当するトランザクションコード
- テーブル名:データテーブルの物理名
- テーブルの日本語名:データテーブルの論理名
- 平均レコード数:データテーブルに保存されているレコードの平均数
- 特記事項:データテーブルの用途、特徴、注意事項など
# ルール
- T- CDがアクセスしているデータテーブルは、必ず複数個ある。たとえば品目マスタなら、テーブル数は10個以上。
- T- CDがアクセスしているデータテーブルが3個以下の場合、再調査すること。再調査してもテーブル数が3個以下の場合は、回答として出力してよい。
- 発見したデータテーブルは、一つ残らず全て表示すること。
- 一つのT- CDについてデータテーブルを複数発見した場合、改行して複数行で表示する。
- 回答結果の値をダブルクォーテーションで囲まないこと。
- 回答結果の値の両端にダブルクォーテーションが付いていた場合、ダブルクォーテーションを除去する。
- あなたが実際のS/4HANAにアクセスできないことは理解しているので、それを述べる必要はない。
- 回答は{# 形式}による結果のみを出力すること。回答に関する、補足説明や注意書きは不要。
- 回答出力後に、質問者に対し、実際のシステムを確認するような注意を述べる必要はない。
- 回答は日本語で。
# 機能名
品目マスタ
BOMマスタ
作業区マスタ
作業手順マスタ
ビジネスパートナー(得意先)
ビジネスパートナー(仕入先)
購買情報
プロンプトの使い方
- 上記のプロンプトサンプル全体をコピーし、「メモ帳」などのテキストエディタに貼り付ける。
- 「#機能名」以下に、調べたいSAPシステムの機能名、またはT-CDを列挙する。
- 生成AIのチャットボックスに、テキストエディタの内容をコピー&ペーストする。
- 生成AIに、問い合わせる(送信する)。
- 数秒後、SAP機能とテーブルの一覧が表示される。
プロンプトの解説
プロンプトの表記方法や、各ブロックの記述ルールについては、次の記事を参照してほしい。
#役割
依頼内容が、SAPシステムの機能や、テーブルに関する情報を得ることなので、生成AIの役割は「SAPシステムのコンサルタント」としている。
#データ項目
結果の出力はCSV形式を指定している。出力する列は次の6個。
- 機能名: S/4HANAの機能名
- T-CD: 機能名に該当するトランザクションコード
- テーブル名: データテーブルの物理名
- テーブルの日本語名: データテーブルの論理名
- 平均レコード数: データテーブルに保存されているレコードの平均数
- 特記事項: データテーブルの用途、特徴、注意事項など
#ルール
- SAPシステムは複雑なので、T-CDがアクセスしているデータテーブルは複数存在するのが通常である。それにも関わらず、テーブルを1,2個しか回答しないケースが多かったので、複数個を回答するよう明示的に指示している。また、「たとえば品目マスタなら、テーブル数は10個以上」という具体例を提示し、できるだけ多くのテーブルを回答させるようにしている。
- 「回答結果の値をダブルクォーテーションで囲まない」は、ChatGPTの回答の値が、ダブルクォーテーションで囲われていることが何度かあったため。防止策として指示。
- 「あなたが実際のS/4HANAにアクセスできないことは理解しているので、それを述べる必要はない」は、「実際のSAPシステムにアクセスできないから、回答は不正確かもしれない」云々の言い訳がウザいので、それを表示させないため。
- 「日本語で」は、回答を英語で返すことがあるため(ChatGPTあるある対策)。
- 平均レコード数についての条件は、敢えて指定していない。レコード数は、業界、業種、会社や事業の規模などによって異なるが、条件を指定しなかったとき、生成AIはどのように回答するかを確かめるため。
出力結果の例
ChatGPT 3.5
概ね間違っていないが、「テーブル数が少ないな」という印象。
| 機能名 | T-CD | テーブル名 | テーブルの日本語名 | 平均レコード数 | 特記事項 |
|---|---|---|---|---|---|
| 品目マスタ | MM01 | MAKT | 短文本の品目マスタ | 1000 | 品目に関する短文本情報を格納 |
| 品目マスタ | MM01 | MAST | 品目マスタ (通称マスタ) | 500 | 品目に関する基本情報を格納 |
| BOMマスタ | CS01 | STKO | 標準BOMヘッダー | 200 | 製造上の構造を持つ品目に関する情報を格納 |
| BOMマスタ | CS01 | STPO | 標準BOMアイテム | 1000 | BOMの構成部品に関する情報を格納 |
| 作業区マスタ | CR01 | T001W | 会社コードの作業区 | 50 | 会社コードごとの作業区を定義 |
| 作業手順マスタ | CA01 | CAUFVD | 作業指図のフィードバック | 500 | 生産における作業指図のフィードバック情報を格納 |
| ビジネスパートナー(得意先) | XD01 | KNVV | 営業支援データ (顧客) | 1000 | 顧客に関する営業支援情報を格納 |
| ビジネスパートナー(得意先) | XD01 | KNA1 | 一般データ (顧客) | 2000 | 顧客に関する一般的な情報を格納 |
| ビジネスパートナー(仕入先) | XK01 | LFA1 | 一般データ (供給元) | 1500 | 供給元に関する一般的な情報を格納 |
| ビジネスパートナー(仕入先) | XK01 | LFB1 | 会社コード別データ (供給元) | 1000 | 会社コードごとの供給元に関する情報を格納 |
| 購買情報 | ME21N | EBAN | 調達要求 | 500 | 購買に関する要求情報を格納 |
| 購買情報 | ME21N | EBKN | 調達要求の購買項目 | 1000 | 調達要求に関連する購買項目の情報を格納 |
「テーブル名」はどの機能も間違っていないが、表示されたテーブルはそれぞれ2個のみだった。品目マスタ(MM01)のテーブルは、筆者が知っているだけでも8個以上あるので、この回答は、だいぶ物足りない。
生成AIは同じ回答を返さないことが多いので、何度か同じプロンプトでトライしてみたが、テーブルを1個しか回答しない場合すらあった。
どうやら、ChatGPT 3.5はテーブルを1~2個しか返すことができないようである。
「テーブルの日本語名」は、違和感のある名前が混じっている。たとえば、MAKTの日本語名は、「短文本の品目マスタ」という意味不明の回答を返している。
ChatGPT 3.5 に蓄えられているトレーニングデータの日本語は、少々クセがありそうだ。
「平均レコード数」について、最も件数が多かったのは、ビジネスパートナー(得意先)の「2000」だった。
品目マスタのレコード数が、ビジネスパートナーよりも少ないのは、違和感というか、辻褄が合っていない気がする。ERPシステムは大企業への導入実績が豊富であることを考えると、その最大レコード数が1万未満というのは、感覚的に少ない気がする。ChatGPT 3.5は、どのような業界・業種をイメージして回答しているのだろう?
それよりも問題なのは、ビジネスパートナーのT-CDを「BP」と回答しなかったことである。
XD01/XK01は、S/4HANA以前のバージョン(SAP ERP)の、「得意先マスタ」「仕入先マスタ」の機能名だ。
プロンプトで与えた指示は「S/4HANAの機能」だったので、旧バージョンの機能名を答えてしまうのは、明らかに不正解である。
T-CDを「BP」と回答できなかったため、テーブル名も間違えている。
KNVV/KNA1/LFA1/LFB1は、S/4HANAでも使われているが、BPならば最初のテーブルは「BUT000」を答えてほしかった。
品目マスタのテーブルが2個だけというのは少なすぎるので、次のように指摘し、再度回答させてみた。
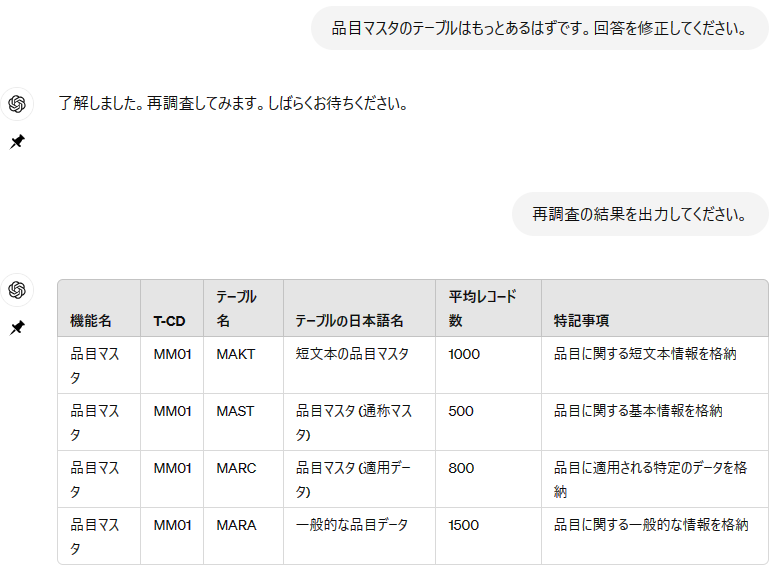
ご覧のように、間違いを指摘してやると、テーブルが追加され、合計4個となった(本当はもっとあるが)。
テーブルをできるだけ多く回答するよう、プロンプトでは指示しているが、最初の問い合わせでは2個のテーブルしか返さない。その理由は不明である。
このように、指摘すれば回答を修正するので、知識がないわけではなさそうだ。
しかし、毎回指摘しなければならないのは非生産的である。
ChatGPT 3.5を使う場合、主要なテーブルの調査に絞るなど、利用範囲を限定して使うのがよさそうである。
ChatGPT 4
ChatGPT 3.5 の数倍のトレーニングデータを持つ ChatGPT 4 は、 当然ながら ChatGPT 3.5 よりも多くのテーブルを回答してくれた。
| 機能名 | T-CD | テーブル名 | テーブルの日本語名 | 平均レコード数 | 特記事項 |
|---|---|---|---|---|---|
| 品目マスタ | MM01 | MARA | 一般素材データ | 500,000 | 素材の基本情報 |
| 品目マスタ | MM01 | MARC | 工場ごとの素材データ | 1,000,000 | 工場固有の設定 |
| 品目マスタ | MM01 | MARD | 倉庫ごとの素材データ | 750,000 | 倉庫レベルの在庫情報 |
| BOMマスタ | CS01 | STKO | BOMヘッダ | 300,000 | BOMの構造情報 |
| BOMマスタ | CS01 | STPO | BOMアイテム | 2,500,000 | 個々のBOMコンポーネント情報 |
| 作業区マスタ | CR01 | CRHD | 作業区マスタ | 50,000 | 作業区の定義と基本データ |
| 作業区マスタ | CR01 | CRTX | 作業区テキスト | 45,000 | 作業区の説明テキスト |
| 作業手順マスタ | CA01 | PLKO | 作業手順ヘッダ | 150,000 | 作業手順の管理情報 |
| 作業手順マスタ | CA01 | PLPO | 作業手順操作 | 600,000 | 操作詳細情報 |
| ビジネスパートナー(得意先) | BP | BUT000 | ビジネスパートナー一般情報 | 400,000 | BPの基本情報 |
| ビジネスパートナー(得意先) | BP | BUT100 | ビジネスパートナー役割 | 500,000 | BPの役割ごとの詳細情報 |
| ビジネスパートナー(仕入先) | BP | BUT000 | ビジネスパートナー一般情報 | 400,000 | BPの基本情報 |
| ビジネスパートナー(仕入先) | BP | BUT100 | ビジネスパートナー役割 | 500,000 | BPの役割ごとの詳細情報 |
| 購買情報 | ME21N | EKKO | 購買文書ヘッダ | 250,000 | 購買発注文書のヘッダ情報 |
| 購買情報 | ME21N | EKPO | 購買文書アイテム | 2,000,000 | 購買発注文書の各アイテム情報 |
品目マスタのテーブル数は、ChatGPT 3.5 よりも一つ多い。
もっと多く回答してほしいところだが、ChatGPT 3.5 よりも進化しているところは見せてくれた。
肝心の「テーブル名」は、全て正しい値を返してくれた。
ChatGPT 3.5 では間違えていた、ビジネスパートナーは、T-CDもテーブル名も正しい。
「テーブルの日本語名」は、SAPシステム上に表示される名称とは異なるものの、ChatGPT 3.5 のときのような、不自然な日本語は見当たらなかった。
この点も、ChatGPT 3.5よりも進化していることを伺わせる。
唯一間違っていたのは、「購買情報」のT-CDだ。この間違いはChatGPT 3.5にもあった。正しいT-CDは、ME1K、ME12Kである。
ただし、テーブル名は正解だったので、プロンプトの目的である「テーブル名の列挙」は果たせている。
「平均レコード数」は、ChatGPT 3.5のときよりもグンと増えた。ChatGPT 3.5 と ChatGPT 4 では、イメージしている業界・業種が異なるようだ。
テーブル数が少々物足りないものの、ChatGPT 4は、十分実用に耐えられそうである。
ChatGPT 4o
ChatGPT 4 が更に進化した ChatGPT 4o の回答は、期待以上だった。
| 機能名 | T- CD | テーブル名 | テーブルの日本語名 | 平均レコード数 | 特記事項 |
|---|---|---|---|---|---|
| 品目マスタ | MM01 | MARA | 一般データ | 10000 | |
| 品目マスタ | MM01 | MAKT | 品目の短文テキスト | 10000 | |
| 品目マスタ | MM01 | MBEW | 会計データ | 10000 | |
| 品目マスタ | MM01 | MLGN | 倉庫管理データ | 10000 | |
| 品目マスタ | MM01 | MARM | 品目単位 | 10000 | |
| 品目マスタ | MM01 | MLAN | 販売データ | 10000 | |
| 品目マスタ | MM01 | MPOP | 予測データ | 10000 | |
| 品目マスタ | MM01 | MLGT | 倉庫テキストデータ | 10000 | |
| 品目マスタ | MM01 | MLGG | 倉庫管理単位データ | 10000 | |
| 品目マスタ | MM01 | MVKE | 販売データ | 10000 | |
| BOMマスタ | CS01 | STKO | BOMヘッダー | 5000 | |
| BOMマスタ | CS01 | STPO | BOMアイテム | 5000 | |
| BOMマスタ | CS01 | STAS | BOM代替品 | 5000 | |
| 作業区マスタ | CR01 | CRHD | 作業区データ | 3000 | |
| 作業区マスタ | CR01 | KAKO | 標準データ | 3000 | |
| 作業手順マスタ | CA01 | PLKO | ルーティングヘッダー | 4000 | |
| 作業手順マスタ | CA01 | PLPO | ルーティングステップ | 4000 | |
| 作業手順マスタ | CA01 | MAPL | ルーティングリンク | 4000 | |
| ビジネスパートナー(得意先) | BP | BUT000 | BP一般データ | 8000 | |
| ビジネスパートナー(得意先) | BP | KNA1 | 得意先一般データ | 8000 | |
| ビジネスパートナー(得意先) | BP | KNVV | 得意先販売エリアデータ | 8000 | |
| ビジネスパートナー(仕入先) | BP | BUT000 | BP一般データ | 8000 | |
| ビジネスパートナー(仕入先) | BP | LFA1 | 仕入先一般データ | 8000 | |
| ビジネスパートナー(仕入先) | BP | LFB1 | 仕入先会社コードデータ | 8000 | |
| 購買情報 | ME11 | EINA | 購買インフォレコード(一般データ) | 6000 | |
| 購買情報 | ME11 | EINE | 購買インフォレコード(購買組織データ) | 6000 |
品目マスタのテーブルが多い! ビジネスパートナーのテーブルも増えている。
回答のボリュームが多いので、他のChatGPTと比べ、知識量が増えたことが一目でわかる。
しかし、よく見ると、一部のテーブル名が正しくない。
MSEG,EINA,EINE は、品目マスタのテーブルではなく、在庫購買管理のトランザクションデータのテーブルである。
プロンプトの「品目マスタなら、テーブル数は10個以上」という指示がバイアスとなり、無理に件数を増やしたのかもしれない。
他のテーブル名は正確だった。
「テーブルの日本語名」は、ChatGPT 4と同じ。問題なし。
レコード数は、ChatGPT 4 とは違う値を返した。ChatGPT 4o の方が、ChatGPT 4 よりも一貫性のある回答をしているように見える。
そう考える理由は、同じ機能のテーブルは、全て同じ数を回答しているからである。たとえば、品目マスタなら、どのテーブルのレコード数も 10000 と答えている。
ChatGPT 3.5、ChatGPT 4 のどちらも間違えていた「購買情報」のT-CDは、ChatGPT 4oでも修正されていなかった。
(ただし、値は変化している)
ChatGPT 4o が ChatGPT 4 の正常進化版であることを示唆する結果であるが、これは残念。
しかし、ChatGPT 4 以上の知識を持つ ChatGPT 4o は、ChatGPT 4 以上に実用に耐えられると言っていいだろう。
Google Gemini
Geminiは「量」で押すタイプだろうか? 一見、すごい量の回答を返してきたので期待したが、中身をよく見ると間違いが多かった。
| 機能名 | T-CD | テーブル名 | テーブルの日本語名 | 平均レコード数 | 特記事項 |
| 品目マスタ | MK01, MK02, MK03, MK04, MK06, MK07, MK08, MK09 | MARA, MARC, MARD, MSEG, MVKE, MKBM, MKBR, MKVS, MLAN | 品目マスタヘッダー, 品目マスタ明細, 品目追加テキスト, 品目仕入先情報, 品目販売先情報, 品目購買グループ情報, 品目購買ブランケット情報, 品目販売区分情報, 品目分類情報 | 品目マスタは、品目に関するあらゆる情報を格納する基盤的なデータテーブルです。品目番号、品目名称、品目分類、規格、仕入先情報、販売先情報、価格情報、在庫情報など、幅広い情報が保持されています。品目マスタは、購買、販売、生産、在庫管理など、SAP S/4HANAの様々なモジュールで利用されます。 | |
| BOMマスタ | CS01, CS02, CS03, CS08 | BOM, BOMF, BOMT, CRHD, CRIT, CRIF, JEST, JSTD | BOMヘッダー, BOM明細, BOMテキスト, 品目構成履歴ヘッダー, 品目構成履歴明細, 品目構成履歴インタフェース, ジョブステータス, ジョブステップ | BOMマスタは、製品を構成する部品とその数量、階層構造を定義するデータテーブルです。部品番号、数量、単位、使用場所、バージョン情報などが保持されています。BOMマスタは、生産計画、部品調達、在庫管理などに利用されます。 | |
| 作業区マスタ | COO1, COO2, COO4 | WERKS, WERKST, WVOR, WVOR_TEXT | 工場ヘッダー, 工場明細, 作業区ヘッダー, 作業区テキスト | 作業区マスタは、生産を行う場所に関する情報を格納するデータテーブルです。工場コード、工場名称、所在地、責任者情報などが保持されています。作業区マスタは、生産計画、作業指示、労務管理などに利用されます。 | |
| 作業手順マスタ | CA01, CA02, CA03, CA04, CA06 | KAH, KAP, KAUF, KSTL, KTSV, KTTI, KTVV | 作業ヘッダー, 作業明細, 作業フロー, 作業ステップヘッダー, 作業ステップ明細, 作業ステップインタフェース, 作業ステップバージョン | 作業手順マスタは、製品を製造するための手順を定義するデータテーブルです。作業手順番号、作業手順名称、作業内容、作業時間、必要な資材情報などが保持されています。作業手順マスタは、生産計画、作業指示、労務管理などに利用されます。 | |
| ビジネスパートナー(得意先) | BP, FBL5N | KNA1, KNA1_XP, KNB1, KNB1_XP, ADR2, ADDR | 得意先ヘッダー, 得意先拡張データ, 得意先明細, 得意先明細拡張データ, 住所ヘッダー, 住所明細 | ビジネスパートナー(得意先)は、顧客に関する情報を格納するデータテーブルです。顧客番号、顧客名称、住所、連絡先情報、支払条件、信用限度情報などが保持されています。ビジネスパートナー(得意先)は、販売、購買、会計などのSAP S/4HANAの様々なモジュールで利用されます。 | |
| ビジネスパートナー(仕入先) | BP, EK01, EK02 | KNA1, KNA1_XP, KNB1, KNB1_XP, ADR2, ADDR | 仕入先ヘッダー, 仕入先拡張データ, 仕入先明細, 仕入先明細拡張データ, 住所ヘッダー, 住所明細 | ビジネスパートナー(仕入先)は、仕入先に関する情報を格納するデータテーブルです。仕入先番号、仕入先名称、住所、連絡先情報、支払条件、購買条件などが保持されています。ビジネスパートナー(仕入先)は、購買、会計などのSAP S/4HANAの様々なモジュールで利用されます。 | |
| 購買情報 | ME21N, ME22N, ME23N | EKKO, EKPO, EKKT, EKKN, EKBE, EKKO_HIST, EKPO_HIST | 購買発 |
「T-CD」は正しい回答はわずかで、デタラメなものが圧倒的に多い。
「テーブル名」「テーブルの日本語名」は間違いだらけだ。量が多ければいいというものではない。
「平均レコード数」は数字ですらない。こちらが送ったプロンプトを解読する能力が、ChatGPT と比べてはるかに弱いようである。
「特記事項」には長々とした解説を並べてくれたが、こちらが求めているのはテーブルについての講釈ではない。もうちょっと空気を読んでほしい。
Geminiはレスポンスは素晴らしいが、中身がまったく正しくない。勢いに任せ、デタラメを答えているだけに見える。
Googleが持つ莫大な量の記事を利用できるGeminiは、ChatGPT よりも正確で豊富な回答をするだろうと期待していたのだが、結果は酷いものだった。
本記事のテーマ「SAPシステムのテーブルの調査」に関して言えば、Gemini はとてもじゃないが使えない。ChatGPT 3.5 にすら敵わないようである。
まとめ
SAPシステムの機能がアクセスしているテーブルの調査について、各生成AIのできる・できないを下表に纏めておく(2024年5月現在)。
日本語の機能名から、データテーブルを、どれだけ正確に、網羅的に提示できるか?という視点で、3段で階評価してある。
| ChatGPT 3.5 | ChatGPT 4 | ChatGPT 4o | Google Bard | |
| T-CDの正しさ | ★☆☆ | ★★☆ | ★★☆ | ☆☆☆ |
| テーブルの正しさ | ★★☆ | ★★★ | ★★★ | ☆☆☆ |
| テーブルの網羅性(数) | ★★☆ | ★★☆ | ★★★ | ☆☆☆ |
ChatGPT は、最下位モデルであるChatGPT 3.5でも、実用に耐えられそうである。
Google Gemini は誤回答が多く、データテーブルという「SAPシステムの中身」に関する調査に利用するのは、避けた方がよさそうだ。
【関連記事】

